12. Hands-On Session 12: Indirect free energy “book-ending”: efficiently correct low-level MM force field results to high-level QDπ
12.1. Learning Objectives
Use sander to perform MM-to-QM/MM equilibrium simulations
Analyze the simulations to calculate a free energy correction
Use sander to perform MM-to-QM/MM nonequilibrium simulations
Analyze the simulations to calculate a free energy correction
12.2. Activities
flowchart LR
%% ===== shared MM inputs =====
A1["MM inputs<br/>mm.parm7 qmmm.parm7<br/>init.rst7 mdin files"]
%% ===== equilibrium branch =====
P1{{"<b>[§12.2.1.1]</b><br/>Prepare groupfile and mdin<br/>sander setup"}}
O1["<b>[from §12.2.1.1]</b><br/>FE groupfiles<br/>bookend_*.groupfile"]
P2{{"<b>[§12.2.1.2]</b><br/>Run MM and QM/MM sampling<br/>sander.MPI"}}
O2["<b>[from §12.2.1.2]</b><br/>MBAR energies<br/>mm_*.mdout qm_*.mdout"]
P3{{"<b>[§12.2.1.3]</b><br/>Analyze MBAR free energy<br/>edgembar-bookend2dats.py edgembar"}}
O3["<b>[from §12.2.1.3]</b><br/>Equilibrium correction<br/>delta-delta-G"]
A1 --> P1
P1 --> O1
O1 --> P2
P2 --> O2
O2 --> P3
P3 --> O3
%% ===== non-equilibrium branch =====
P4{{"<b>[§12.2.2.1]</b><br/>Run MM lambda=0 sampling<br/>sander"}}
O4["<b>[from §12.2.2.1]</b><br/>MM ensemble trajectory<br/>mm.nc"]
P5{{"<b>[§12.2.2.2]</b><br/>Split trajectory and build switching files<br/>cpptraj sander setup"}}
O5["<b>[from §12.2.2.2]</b><br/>Switching groupfile and frames<br/>switch.groupfile frameblk*.nc"]
P6{{"<b>[§12.2.2.3]</b><br/>Run MM-to-QM/MM switching<br/>sander.MPI"}}
O6["<b>[from §12.2.2.3]</b><br/>Final work values<br/>mm.mdout qm.mdout"]
P7{{"<b>[§12.2.2.4]</b><br/>Analyze with Jarzynski equality<br/>edgembar-bookend2dats.py edgembar"}}
O7["<b>[from §12.2.2.4]</b><br/>Non-equilibrium correction<br/>delta-delta-G"]
A1 --> P4
P4 --> O4
O4 --> P5
P5 --> O5
O5 --> P6
P6 --> O6
O6 --> P7
P7 --> O7
classDef file fill:#fff7e6,stroke:#d98c00,stroke-width:1.5px,color:#111;
classDef program fill:#e8f1ff,stroke:#1f77b4,stroke-width:1.8px,color:#111;
classDef result fill:#eaf7ea,stroke:#2ca02c,stroke-width:1.5px,color:#111;
class A1 file;
class P1,P2,P3,P4,P5,P6,P7 program;
class O1,O2,O3,O4,O5,O6,O7 result;
12.2.1. Equilibrium Bookending
Suppose you want to calculate a change in free energy via an alchemical pathway using an ab initio or semiempirical method rather than a molecular mechanical force field.
Unlike a molecular mechanical force field, one can’t directly sample quantum mechanical methods in an alchemical pathway (which may require fractional nuclear charges and fractional numbers of electrons as atoms appear or disappear).
To overcome this limitation, one uses an “indirect” reference potential approach, whereby the free energy is calculated with the low-level force field that is fast enough to sample the transformation for an extended period of time with multiple trials, and the high-level QM contribution to the free energy is calculated as a correction to the physical end-states. A depiction of the bookend corrections is shown in the following figure.
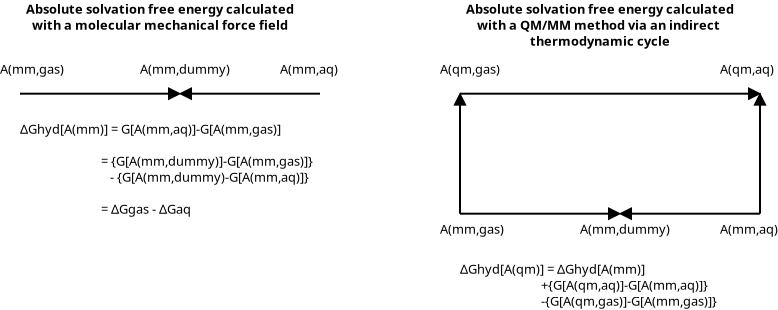
The left-side of the figure shows a thermodynamic cycle for calculating an absolute solvation free energy using a MM force field. The equation below it is the mathematical representation of the cycle. The “cycle” performs real-to-dummy state transformations in two environments: aqueous phase and gas phase. The direction of the arrows are chosen so the lambda=0 and lambda=1 states are the real and dummy states, respectively. The right-side shows how to calculate the hydration free energy using a QM/MM method. The complicated alchemical sampling is performed with the MM force field and the MM-to-QM/MM transformations correct the real-state free energies. These “bookend” corrections can be run with far less sampling because there are no chemical or alchemical changes.
The bookend transformations transform the potential energy from a MM force field to a QM/MM potential. A bookend transformation is required for each “real state”. Mathematically, it is given by the following equation
where “tgt” and “ref” denote the target and reference environments.
12.2.1.1. Preparing the input files
The bookend free energy simulations are simple, linear transformations U(λ)=U(0)+λ[U(1)-U(0)] performed with sander. The free energy infrastructure in sander is different from pmemd. In general, sander uses a groupfile to read the λ=0 and λ=1 states from 2 cooresponding sets of mdin, rst7, and parm7 files.
Download
Example Files. The package includes files used to calculate Eqs. \eqref{E:BEaq} and \eqref{E:BEgas} for acetic acid in which a MM potential is transformed to GFN2-xTB QM/MM with QDπ2 machine learning corrections. The contents of the files are essentially those shown in Figures 2 and 3.You can unpack the files by typing:
tar -xzf example_mm2qmmm.inputs.tar.gz. This will create a directory./example_mm2qmmm/.
The groupfile should contain 2 lines. The first line is the MM (λ=0) state. The second is the QM/MM (λ=1) state. A separate groupfile is used for each value of clambda. It is often sufficient to use 5 lambda values: 0.00, 0.20, 0.40, 0.60, 0.80, 1.00. Notice that both states read the exact same input coordinates.
-O -p mm.parm7 -c init.rst7 -i mm_0.00.mdin -o mm_0.00.mdout -r mm_0.00.rst7 -x mm_0.00.nc -inf mm_0.00.mdinfo
-O -p qmmm.parm7 -c init.rst7 -i qm_0.00.mdin -o qm_0.00.mdout -r qm_0.00.rst7 -x qm_0.00.nc -inf qm_0.00.mdinfo
The mdin file should activate the free energy infrastructure (ifce=1). There are 2 mdin files for each value of clambda (the MM and QM/MM states). An example MM template mdin file is shown below. The QM/MM mdin file should be the same thing as the MM mdin file; however, one sets ifqnt=1 rather than ifqnt=0. Furthermore, the MM and QM/MM simulations both don’t need to wite a trajectory file because they both encounter the same sets of coordinates, so one should ntwx=0 in the QM/MM mdin file while setting ntwx to the desired print frequency in the MM mdin file.
Equilibrium TI analysis
&cntrl
! IO =======================================
irest = 1 ! 0 = start, 1 = restart
ntx = 5 ! 1 = start, 5 = restart
ntxo = 1 ! read/write rst as formatted file
iwrap = 1 ! wrap crds to unit cell
ioutfm = 1 ! write mdcrd as netcdf
ntpr = 50 ! mdout print freq
ntwx = 0 ! mdcrd print freq
ntwr = 500 ! rst print freq
ntwv = 0
! DYNAMICS =================================
! - - ATTN: a 2 fs timestep only works if the parm7 was modified with hydrogen mass repartitioning - -
imin = 0 ! Run dynamics
dt = 0.001 ! ps/step
nstlim = 10000 ! number of time steps (per simulation)
ntb = 1 ! 1=periodic box
! TEMPERATURE ==============================
temp0 = 298 ! target temp
! gamma_ln = 5.0 ! Langevin collision freq
! ntt = 3 ! thermostat (3=Langevin)
! Use middle scheme rather than the default leapfrog integrator
! so the middle scheme people dont complain. Supposedly its more stable.
ntt = 0
ischeme = 1 ! middle scheme
ithermostat = 1 ! Langevin
therm_par = 5.0 ! Langevin collision freq
! PRESSURE ================================
! If we really wanted to run NPT, we'd need to use the Monte Carlo barostat because
! the QM/MM infrastructure doesn't contribute to the virial
ntp = 0 !0=off 1=isotropic scaling
! taup = 2.0 ! pressure relaxation time
! pres0 = 1.013 ! pressure (bar), 1.013 bar/atm
! barostat = 1 ! barostat (1=Berendsen, 2=MC)
! SHAKE ====================================
ntc = 2 ! 1=no shake, 2=HX constrained, 3=all constrained
ntf = 1 ! 1=cpt all bond E, 2=ignore HX bond E, 3=ignore all bond E
noshakemask=':1'
! MISC =====================================
cut = 10
ig = -1
ifqnt = 0
! TI =======================================
icfe = 1 ! interpret groupfile as being a FE simulation; first group is MM, second is QM/MM
clambda = 0.00 ! Manually set lambda. 0=MM, 1=QM/MM
ifmbar = 1 ! print the lam=0 and lam=1 energies
bar_intervall = 50
bar_l_min = 0
bar_l_max = 1
bar_l_incr = 1
dynlmb = 0
ntave = 0
/
&qmmm
qm_theory = 'AM1D'
qmmask = ':1'
qmcharge = 0
spin = 1
qmshake = 0
qm_ewald = 1
qmmm_switch = 1
verbosity = 0
/
12.2.1.2. Running the simulations
You should equilibrate each lambda state and perform multiple trials
of production. The command should be something like:
OMP_NUM_THREADS=1 mpirun -n 2 sander.MPI -ng 2 -groupfile bookend_0.00.groupfile.
Replace mpirun with srun, if appropriate. Use more processors (a multiple
of 2), if necessary. Most semiempirical methods do not scale well beyond
4 cores, so the most number of cores you’d likely ever use is 8.
12.2.1.3. Analyzing the results
The mdout files generated with the provided template mdin file will contain the values of U(0) and U(1) in the MBAR energy analysis output that you can use to analyze the free energy. The potential energy of an arbitrary λ state is directly calculated from these values: U = λ U(0) + (1-λ) U(1). The “DVDL” values are similarly calculated: dU(λ)/dλ=U(1)-U(0).
As a convenience, the edgembar-bookend2dats.py script (a part of FE-ToolKit) reads your mdout files, calculates the appropriate MBAR energies and DVDL values and writes a series of efep_*.dat and dvdl_*.dat data files. These data files are the format used by edgembar to calculate the free energy, as discussed in Analyzing ABFE Calculations (Tyk2)
An example using edgembar-bookend2dats.py follows. The example reads the MM mdout files (it could be the QM/MM mdout files – it doesn’t matter), and writes the data files to the LIG~LIGqm/environment/t01 directory.
edgembar-bookend2dats.py -o LIG~LIGqm/aq/t01 $(ls t01/aq/mm_*.mdout)
edgembar-bookend2dats.py -o LIG~LIGqm/gas/t01 $(ls t01/gas/mm_*.mdout)
One could prepare edgembar XML input files to correct MM results with the bookend simulation data by introducing them as an additional stage; however, in the above example, I call the MM ligand “LIG” and the QM/MM ligand “LIGqm”. If it were included as an additional stage, then the reported edge free energy of each ligand is the QM/MM-corrected value. If it is included as a separately-named ligand, then one can see the MM and boookend-correction as separate free energy values in the graph analysis.
As specific examples, one way to setup your directory structure for use with edgembar is shown below, where the “LIG~null” is the transformation from a real ligand to a dummy state, the environment is either “aq” or “gas”, the stage is either “unified” or “bookend”, and the last subdirectory indicated the independent trial. Be aware that you will need to pay special attention to get the sign of the free energies correct. You’ll either need to switch the order of the bookend lambda values to negate the sign of the bookend correction, or your edgembar XML input file will need to reverse the list of bookend states.
./LIG~null/aq/unified/t01/efep_*_*.dat
./LIG~null/aq/unified/t02/efep_*_*.dat
./LIG~null/aq/unified/t03/efep_*_*.dat
./LIG~null/aq/unified/t04/efep_*_*.dat
./LIG~null/aq/bookend/t01/efep_*_*.dat
./LIG~null/aq/bookend/t02/efep_*_*.dat
./LIG~null/aq/bookend/t03/efep_*_*.dat
./LIG~null/aq/bookend/t04/efep_*_*.dat
./LIG~null/gas/unified/t01/efep_*_*.dat
./LIG~null/gas/unified/t02/efep_*_*.dat
./LIG~null/gas/unified/t03/efep_*_*.dat
./LIG~null/gas/unified/t04/efep_*_*.dat
./LIG~null/gas/bookend/t01/efep_*_*.dat
./LIG~null/gas/bookend/t02/efep_*_*.dat
./LIG~null/gas/bookend/t03/efep_*_*.dat
./LIG~null/gas/bookend/t04/efep_*_*.dat
The edgembar XML file would be organized as follows:
<?xml version="1.0" ?>
<edge name="LIG~null">
<env name="target"> <!-- "aq" -->
<stage name="unified">
<trial name="t01">
<dir>./LIG~null/aq/unified/t01</dir>
<ene>0.00000000</ene>
<ene>0.10000000</ene>
<ene>0.20000000</ene>
<ene>0.30000000</ene>
<ene>0.40000000</ene>
<ene>0.50000000</ene>
<ene>0.60000000</ene>
<ene>0.70000000</ene>
<ene>0.80000000</ene>
<ene>0.90000000</ene>
<ene>1.00000000</ene>
</trial>
<! -- Analogous for trials t02 t03 t04 -->
</stage>
<stage>
<!-- reverse the order of the states to negate the energy -->
<dir>./LIG~null/aq/bookend/t01</dir>
<ene>1.00000000</ene>
<ene>0.80000000</ene>
<ene>0.60000000</ene>
<ene>0.40000000</ene>
<ene>0.20000000</ene>
<ene>0.00000000</ene>
</stage>
</env>
<env name="reference">
<!-- Analogous for env name="reference" (aka "gas") -->
</env>
</edge>
Alternatively, you could organize the directories such that the QM/MM representation of the ligand has a different ligand name.
./LIG~null/aq/unified/t01/efep_*_*.dat
./LIG~null/aq/unified/t02/efep_*_*.dat
./LIG~null/aq/unified/t03/efep_*_*.dat
./LIG~null/aq/unified/t04/efep_*_*.dat
./LIG~LIGqm/aq/bookend/t01/efep_*_*.dat
./LIG~LIGqm/aq/bookend/t02/efep_*_*.dat
./LIG~LIGqm/aq/bookend/t03/efep_*_*.dat
./LIG~LIGqm/aq/bookend/t04/efep_*_*.dat
./LIG~null/gas/unified/t01/efep_*_*.dat
./LIG~null/gas/unified/t02/efep_*_*.dat
./LIG~null/gas/unified/t03/efep_*_*.dat
./LIG~null/gas/unified/t04/efep_*_*.dat
./LIG~LIGqm/gas/bookend/t01/efep_*_*.dat
./LIG~LIGqm/gas/bookend/t02/efep_*_*.dat
./LIG~LIGqm/gas/bookend/t03/efep_*_*.dat
./LIG~LIGqm/gas/bookend/t04/efep_*_*.dat
Edgembar would then have 2 input files:
<?xml version="1.0" ?>
<edge name="LIG~null">
<env name="target"> <!-- "aq" -->
<stage name="unified">
<trial name="t01">
<dir>./LIG~null/aq/unified/t01</dir>
<ene>0.00000000</ene>
<ene>0.10000000</ene>
<ene>0.20000000</ene>
<ene>0.30000000</ene>
<ene>0.40000000</ene>
<ene>0.50000000</ene>
<ene>0.60000000</ene>
<ene>0.70000000</ene>
<ene>0.80000000</ene>
<ene>0.90000000</ene>
<ene>1.00000000</ene>
</trial>
<! -- Analogous for trials t02 t03 t04 -->
</stage>
</env>
<env name="reference">
<!-- Analogous for env name="reference" (aka "gas") -->
</env>
</edge>
<?xml version="1.0" ?>
<edge name="LIG~LIGqm">
<env name="target"> <!-- "aq" -->
<stage name="bookend">
<trial name="t01">
<dir>./LIG~null/aq/bookend/t01</dir>
<ene>0.00000000</ene>
<ene>0.20000000</ene>
<ene>0.40000000</ene>
<ene>0.60000000</ene>
<ene>0.80000000</ene>
<ene>1.00000000</ene>
</trial>
<! -- Analogous for trials t02 t03 t04 -->
</stage>
</env>
<env name="reference">
<!-- Analogous for env name="reference" (aka "gas") -->
</env>
</edge>
In this case, you don’t have to reverse the sign of the bookend states because edgembar aligns the “arrows in the thermodynamic cycle” by the transformation name, e.g., “LIG~LIGqm”. You WOULD need to reverse the states if the transformation name was “LIGqm~LIG”.
12.2.2. Non-Equilibrium Bookending
This activity is almost the same as Calculate a bookend correction from equilibrium sampling, which should be considered a mandatory prerequisite. In brief, we presume that we calculated an absolute binding free energy with a molecular mechanical force field, and we seek to correct the hydration free energy with a “bookend correction”. The correction is an application of the “indirect method” for calculating free energies from a reference potential.
where “tgt” and “ref” denote the target and reference environments.
The present activity calculates the correction by analyzing nonequilibrium sampling with Jarzynski’s equality. Nonequilibrium sampling in this context means that the alchemical coordinate is time-dependent λ(t). Specifically, λ uniformly scales from λmin-to-λmax (typically 0-to-1) during the course of a simulation – a so-called “switching simulation”.
A brief overview of the procedure is: * Perform a MM simulation and periodically save the coordinates and velocities to the trajectory file * For each frame, perform a short MM-to-QM/MM switching simulation * Each switching simulation produces a single “work value” * Calculate the free enery from the collection of work values using Jarzinski’s equality.
The functional form of Jarzinski’s equality is quite similar to exponential averaging encountered in equilibrium simulation.
The angle brackets represent an average over many switching simulations whose starting coordinates are drawn from the MM ensemble (the ensemble of the λ=0 state). Each switching simulation produces a single “work value”, W.
In practice, the time integration is discretized τ = ∆t×nstlim, where ∆t is the time step and nstlim is the number of steps. If one assumes that the masses are independent of λ, then H(r(t);λ(t)) can be replaced with U(r(t);λ(t)), and the work can be expressed by the following summation. The time steps are indexed from 0 to nstlim-1, such that the elapsed time at step n is t=n∆t.
The derivative is the thermodynamic gradient normally used to evaluate the free energy from thermodynamic integration; however, it only contributes to the nonequilibrum work when λ changes between consecutive time steps. In sander, the time dependence of λ is controlled with the dynlmb and ntave variables. Specifically, the value of λ is incremented by dynlmb once every ntave steps. If nstlim is an integer multiple of ntave, then λ will be incremented a total of Nincr = nstlim/ntave times, and each increment increases λ by dynlam = (λmax−λmin)/Nincr. One can rewrite the summation to include only the subset of samples contributing a nonzero value to the work (i.e., the samples whose time step is a multiple of ntave)
12.2.2.1. The MM (λ=0) simulation
The switching simulations need an ensemble of MM starting configurations. You often need 500-or-more starting structures. When running the MM simulation, you should save both the coordinates and velocities to the trajectory file. You can do this by setting ntwv=-1 and ntwx=N, where N is the number of steps between writes to the trajectory file. It’s often better to run the MM simulation for longer and write to the trajectory file infrequently so your trajectory contains statistically independent samples and your trajectory adequately samples the MM landscape.
Each switching simulation is completely independent; therefore, if you had access to large number of processors, you could you cpptraj to write each frame of the trajectory file as a restart file. You could then use each restart file to initiate a switching simulation in a trivially-parallelized manner. On the other hand, this strategy produces a excessive number of files, which is inconvenient to manage.
The following example shows how to write a series of restart files from a trajectory file using cpptraj.
[user@computer] cpptraj
> parm mm.parm7
> trajin mm.nc
> trajout frame.rst7 restart keepext
> run
> quit
[user@computer] ls frame.*.rst7
frame.1.rst7 frame.2.rst7 frame.3.rst7 frame.4.rst7 [...]
Alternatively, sander allows you to read a trajectory file (set imin=6 and specify the trajectory file on the command line with the -y option). By setting imin=6, sander will run a simulation departing from each frame of the trajectory file, and all the outputs are effectively concatenated into a single file. To parallelize this strategy, use cpptraj to split the trajectory file into several smaller trajectory files.
[user@computer] cpptraj
> parm mm.parm7
> trajin mm.nc
> trajout frameblk1.nc netcdf onlyframes 1-100
> trajout frameblk2.nc netcdf onlyframes 101-200
> trajout frameblk3.nc netcdf onlyframes 201-300
> trajout frameblk4.nc netcdf onlyframes 301-400
> run
> quit
[user@computer] ls frame.*.nc
frameblk1.nc frameblk2.nc frameblk3.nc frameblk4.nc
12.2.2.2. Preparing the switching simulation files
The bookend free energy simulations are simple, linear transformations U(λ)=U(0)+λ[U(1)-U(0)] performed with sander. The free energy infrastructure in sander is different from pmemd. In general, sander uses a groupfile to read the λ=0 and λ=1 states from 2 cooresponding sets of mdin, rst7, and parm7 files.
The groupfile should contain 2 lines. The first line is the MM (λ=0) state. The second is the QM/MM (λ=1) state. The groupfile will look something like this:
-O -p mm.parm7 -c init.rst7 -i mm.mdin -o mm.mdout -r mm.rst7 -x tmpmm.nc -inf mm.mdinfo -y mm.nc
-O -p qmmm.parm7 -c init.rst7 -i qm.mdin -o qm.mdout -r qm.rst7 -x tmpqm.nc -inf qm.mdinfo -y mm.nc
The mdin file should activate the free energy infrastructure (ifce=1). There are 2 mdin files for each value of clambda (the MM and QM/MM states). An example MM template mdin file is shown below. The QM/MM mdin file should be the same thing as the MM mdin file; however, one sets ifqnt=1 rather than ifqnt=0.
Switching simulation; assumes the input MM trajectory has velocities saved with ntwv=-1
&cntrl
! IO =======================================
irest = 1 ! 0 = start, 1 = restart
ntx = 5 ! 1 = start, 5 = restart
ntxo = 1 ! read/write rst as formatted file
iwrap = 1 ! wrap crds to unit cell
ioutfm = 1 ! write mdcrd as netcdf
ntpr = 1 ! mdout print freq
ntwx = 0 ! mdcrd print freq
ntwr = 500 ! rst print freq
ntwv = 0
! DYNAMICS =================================
! - - ATTN: a 2 fs timestep only works if the parm7 was modified with hydrogen mass repartitioning - -
imin = 6 ! Read input trajectory file and run dynamics
dt = 0.001 ! ps/step
nstlim = 500 ! number of time steps (per simulation)
ntb = 1 ! 1=periodic box
! TEMPERATURE ==============================
temp0 = 298 ! target temp
! gamma_ln = 5.0 ! Langevin collision freq
! ntt = 3 ! thermostat (3=Langevin)
! Use middle scheme rather than the default leapfrog integrator
! so the middle scheme people dont complain. Supposedly its more stable.
ntt = 0
ischeme = 1 ! middle scheme
ithermostat = 1 ! Langevin
therm_par = 5.0 ! Langevin collision freq
! PRESSURE ================================
! If we really wanted to run NPT, we'd need to use the Monte Carlo barostat because
! the QM/MM infrastructure doesn't contribute to the virial
ntp = 0 !0=off 1=isotropic scaling
! taup = 2.0 ! pressure relaxation time
! pres0 = 1.013 ! pressure (bar), 1.013 bar/atm
! barostat = 1 ! barostat (1=Berendsen, 2=MC)
! SHAKE ====================================
ntc = 2 ! 1=no shake, 2=HX constrained, 3=all constrained
ntf = 1 ! 1=cpt all bond E, 2=ignore HX bond E, 3=ignore all bond E
noshakemask=':1'
! MISC =====================================
cut = 10
ig = -1
ifqnt = 0
! TI =======================================
icfe = 1 ! interpret groupfile as being a FE simulation; first group is MM, second is QM/MM
clambda = 0 ! Manually set lambda. 0=MM, 1=QM/MM
dynlmb = 0
ntave = 1 ! Change lambda every step
ijarzynski = 1 ! Setup other input variables automatically and report the final work value
/
&qmmm
qm_theory = 'AM1D'
qmmask = ':1'
qmcharge = 0
spin = 1
qmshake = 0
qm_ewald = 1
qmmm_switch = 1
verbosity = 0
/
12.2.2.3. Running the simulations
You should equilibrate each lambda state and perform multiple trials
of production. The command should be something like:
OMP_NUM_THREADS=1 mpirun -n 2 sander.MPI -ng 2 -groupfile switch.groupfile.
Replace mpirun with srun, if appropriate. Use more processors (a multiple
of 2), if necessary. Most semiempirical methods do not scale well beyond
4 cores, so the most number of cores you’d likely ever use is 8.
12.2.2.4. Analyzing the results
The mdout files generated with the provided template mdin file will contain a line reading “Final work value:” at the end of each switching simulation. If you set imin=6 and read a trajectory with the -y option, then there will be multiple occurances of “Final work value:”. You can simply grep these lines out of the mdout files for analysis. Alternatively, you can use the edgembar-bookend2dats.py script (a part of FE-ToolKit) to read your mdout files, and write the MBAR energies and DVDL values and write the necessary efep_*.dat data files. These data files are the format used by edgembar to calculate the free energy, as discussed in Analyzing ABFE Calculations (Tyk2)
The calculation of the free energies from Jarzynski’s equality can use the exact same infrastructure as computing the free energy from exponential averaging. You need generate 2 files per trial: efep_0.0_0.0.dat and efep_0.0_1.0.dat. The file format efep_A_B.dat means that the file contains the energy of state B for the samples drawn from state A. The efep_0.0_0.0.dat file contains 2 columns: the first column is a float or integer representing the time (or time step), and the second column should be 0.0. The efep_0.0_1.0.dat file also contains 2 columns, and it should have the same number of rows, but the energy values are the work values extracted from the mdout file.
An example using edgembar-bookend2dats.py follows. The example reads the MM mdout files (it could be the QM/MM mdout files – it doesn’t matter), and writes the data files to the LIG~LIGqm/environment/t01 directory.
edgembar-bookend2dats.py -o LIG~LIGqm/aq/t01 $(ls t01/aq/mm_*.mdout)
edgembar-bookend2dats.py -o LIG~LIGqm/gas/t01 $(ls t01/gas/mm_*.mdout)
One can then create edgembar XML inputfiles and run the edgembar program to produce the free energy value.